| // Copyright 2022 the Vello Authors |
| // SPDX-License-Identifier: Apache-2.0 OR MIT |
| |
| //! Vello is an experimental 2d graphics rendering engine written in Rust, using [`wgpu`]. |
| //! It efficiently draws large 2d scenes with interactive or near-interactive performance. |
| //! |
| //! 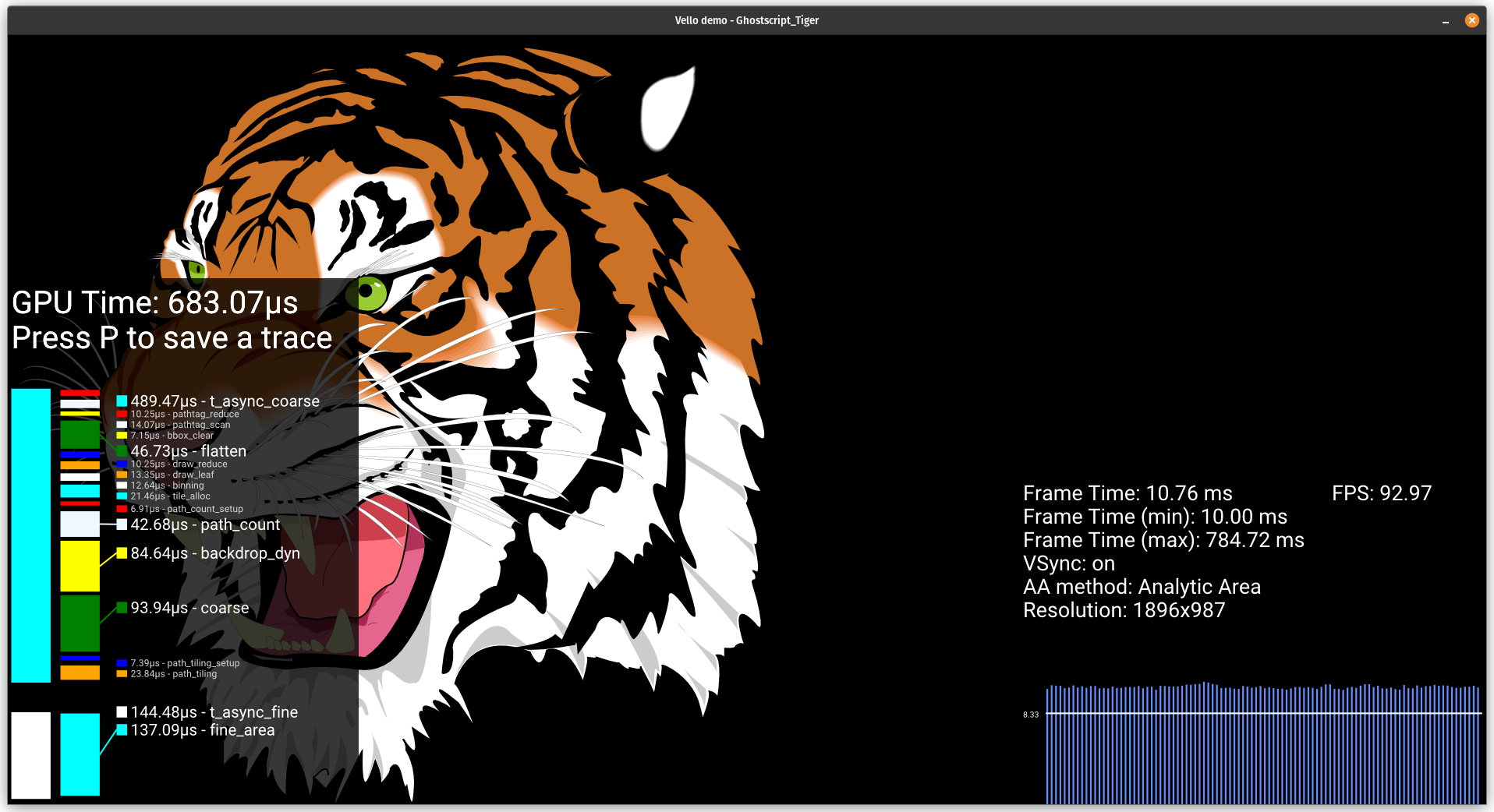 |
| //! |
| //! |
| //! ## Motivation |
| //! |
| //! Vello is meant to fill the same place in the graphics stack as other vector graphics renderers like [Skia](https://skia.org/), [Cairo](https://www.cairographics.org/), and its predecessor project [Piet](https://www.cairographics.org/). |
| //! On a basic level, that means it provides tools to render shapes, images, gradients, texts, etc, using a PostScript-inspired API, the same that powers SVG files and [the browser `<canvas>` element](https://developer.mozilla.org/en-US/docs/Web/API/CanvasRenderingContext2D). |
| //! |
| //! Vello's selling point is that it gets better performance than other renderers by better leveraging the GPU. |
| //! In traditional PostScript-style renderers, some steps of the render process like sorting and clipping either need to be handled in the CPU or done through the use of intermediary textures. |
| //! Vello avoids this by using prefix-scan algorithms to parallelize work that usually needs to happen in sequence, so that work can be offloaded to the GPU with minimal use of temporary buffers. |
| //! |
| //! This means that Vello needs a GPU with support for compute shaders to run. |
| //! |
| //! |
| //! ## Getting started |
| //! |
| //! Vello is meant to be integrated deep in UI render stacks. |
| //! While drawing in a Vello scene is easy, actually rendering that scene to a surface setting up a wgpu context, which is a non-trivial task. |
| //! |
| //! To use Vello as the renderer for your PDF reader / GUI toolkit / etc, your code will have to look roughly like this: |
| //! |
| //! ```ignore |
| //! // Initialize wgpu and get handles |
| //! let (width, height) = ...; |
| //! let device: wgpu::Device = ...; |
| //! let queue: wgpu::Queue = ...; |
| //! let surface: wgpu::Surface<'_> = ...; |
| //! let texture_format: wgpu::TextureFormat = ...; |
| //! let mut renderer = Renderer::new( |
| //! &device, |
| //! RendererOptions { |
| //! surface_format: Some(texture_format), |
| //! use_cpu: false, |
| //! antialiasing_support: vello::AaSupport::all(), |
| //! num_init_threads: NonZeroUsize::new(1), |
| //! }, |
| //! ).expect("Failed to create renderer"); |
| //! |
| //! // Create scene and draw stuff in it |
| //! let mut scene = vello::Scene::new(); |
| //! scene.fill( |
| //! vello::peniko::Fill::NonZero, |
| //! vello::Affine::IDENTITY, |
| //! vello::Color::rgb8(242, 140, 168), |
| //! None, |
| //! &vello::Circle::new((420.0, 200.0), 120.0), |
| //! ); |
| //! |
| //! // Draw more stuff |
| //! scene.push_layer(...); |
| //! scene.fill(...); |
| //! scene.stroke(...); |
| //! scene.pop_layer(...); |
| //! |
| //! // Render to your window/buffer/etc. |
| //! let surface_texture = surface.get_current_texture() |
| //! .expect("failed to get surface texture"); |
| //! renderer |
| //! .render_to_surface( |
| //! &device, |
| //! &queue, |
| //! &scene, |
| //! &surface_texture, |
| //! &vello::RenderParams { |
| //! base_color: Color::BLACK, // Background color |
| //! width, |
| //! height, |
| //! antialiasing_method: AaConfig::Msaa16, |
| //! }, |
| //! ) |
| //! .expect("Failed to render to surface"); |
| //! surface_texture.present(); |
| //! ``` |
| //! |
| //! See the [`examples/`](https://github.com/linebender/vello/tree/main/examples) folder to see how that code integrates with frameworks like winit and bevy. |
| |
| #[cfg(feature = "wgpu")] |
| mod cpu_dispatch; |
| #[cfg(feature = "wgpu")] |
| mod cpu_shader; |
| mod recording; |
| mod render; |
| mod scene; |
| mod shaders; |
| #[cfg(feature = "wgpu")] |
| mod wgpu_engine; |
| |
| #[cfg(feature = "wgpu")] |
| use std::num::NonZeroUsize; |
| |
| /// Styling and composition primitives. |
| pub use peniko; |
| /// 2D geometry, with a focus on curves. |
| pub use peniko::kurbo; |
| |
| #[doc(hidden)] |
| pub use skrifa; |
| |
| pub mod glyph; |
| |
| #[cfg(feature = "wgpu")] |
| pub mod util; |
| |
| pub use render::Render; |
| pub use scene::{DrawGlyphs, Scene}; |
| #[cfg(feature = "wgpu")] |
| pub use util::block_on_wgpu; |
| |
| pub use recording::{ |
| BufferProxy, Command, ImageFormat, ImageProxy, Recording, ResourceId, ResourceProxy, ShaderId, |
| }; |
| pub use shaders::FullShaders; |
| #[cfg(feature = "wgpu")] |
| use wgpu_engine::{ExternalResource, WgpuEngine}; |
| |
| /// Temporary export, used in `with_winit` for stats |
| pub use vello_encoding::BumpAllocators; |
| #[cfg(feature = "wgpu")] |
| use wgpu::{Device, Queue, SurfaceTexture, TextureFormat, TextureView}; |
| #[cfg(all(feature = "wgpu", feature = "wgpu-profiler"))] |
| use wgpu_profiler::{GpuProfiler, GpuProfilerSettings}; |
| |
| /// Catch-all error type. |
| pub type Error = Box<dyn std::error::Error>; |
| |
| /// Specialization of `Result` for our catch-all error type. |
| pub type Result<T> = std::result::Result<T, Error>; |
| |
| /// Represents the antialiasing method to use during a render pass. |
| #[derive(Copy, Clone, PartialEq, Eq)] |
| pub enum AaConfig { |
| Area, |
| Msaa8, |
| Msaa16, |
| } |
| |
| /// Represents the set of antialiasing configurations to enable during pipeline creation. |
| pub struct AaSupport { |
| pub area: bool, |
| pub msaa8: bool, |
| pub msaa16: bool, |
| } |
| |
| impl AaSupport { |
| pub fn all() -> Self { |
| Self { |
| area: true, |
| msaa8: true, |
| msaa16: true, |
| } |
| } |
| |
| pub fn area_only() -> Self { |
| Self { |
| area: true, |
| msaa8: false, |
| msaa16: false, |
| } |
| } |
| } |
| |
| impl FromIterator<AaConfig> for AaSupport { |
| fn from_iter<T: IntoIterator<Item = AaConfig>>(iter: T) -> Self { |
| let mut result = Self { |
| area: false, |
| msaa8: false, |
| msaa16: false, |
| }; |
| for config in iter { |
| match config { |
| AaConfig::Area => result.area = true, |
| AaConfig::Msaa8 => result.msaa8 = true, |
| AaConfig::Msaa16 => result.msaa16 = true, |
| } |
| } |
| result |
| } |
| } |
| |
| /// Renders a scene into a texture or surface. |
| #[cfg(feature = "wgpu")] |
| pub struct Renderer { |
| #[cfg_attr(not(feature = "hot_reload"), allow(dead_code))] |
| options: RendererOptions, |
| engine: WgpuEngine, |
| shaders: FullShaders, |
| blit: Option<BlitPipeline>, |
| target: Option<TargetTexture>, |
| #[cfg(feature = "wgpu-profiler")] |
| pub profiler: GpuProfiler, |
| #[cfg(feature = "wgpu-profiler")] |
| pub profile_result: Option<Vec<wgpu_profiler::GpuTimerQueryResult>>, |
| } |
| |
| /// Parameters used in a single render that are configurable by the client. |
| pub struct RenderParams { |
| /// The background color applied to the target. This value is only applicable to the full |
| /// pipeline. |
| pub base_color: peniko::Color, |
| |
| /// Dimensions of the rasterization target |
| pub width: u32, |
| pub height: u32, |
| |
| /// The anti-aliasing algorithm. The selected algorithm must have been initialized while |
| /// constructing the `Renderer`. |
| pub antialiasing_method: AaConfig, |
| } |
| |
| #[cfg(feature = "wgpu")] |
| pub struct RendererOptions { |
| /// The format of the texture used for surfaces with this renderer/device |
| /// If None, the renderer cannot be used with surfaces |
| pub surface_format: Option<TextureFormat>, |
| |
| /// If true, run all stages up to fine rasterization on the CPU. |
| // TODO: Consider evolving this so that the CPU stages can be configured dynamically via |
| // `RenderParams`. |
| pub use_cpu: bool, |
| |
| /// Represents the enabled set of AA configurations. This will be used to determine which |
| /// pipeline permutations should be compiled at startup. |
| pub antialiasing_support: AaSupport, |
| |
| /// How many threads to use for initialisation of shaders. |
| /// |
| /// Use `Some(1)` to use a single thread. This is recommended when on macOS |
| /// (see <https://github.com/bevyengine/bevy/pull/10812#discussion_r1496138004>) |
| /// |
| /// Set to `None` to use a heuristic which will use many but not all threads |
| /// |
| /// Has no effect on WebAssembly |
| pub num_init_threads: Option<NonZeroUsize>, |
| } |
| |
| #[cfg(feature = "wgpu")] |
| impl Renderer { |
| /// Creates a new renderer for the specified device. |
| pub fn new(device: &Device, options: RendererOptions) -> Result<Self> { |
| let mut engine = WgpuEngine::new(options.use_cpu); |
| // If we are running in parallel (i.e. the number of threads is not 1) |
| if options.num_init_threads != NonZeroUsize::new(1) { |
| #[cfg(not(target_arch = "wasm32"))] |
| engine.use_parallel_initialisation(); |
| } |
| let shaders = shaders::full_shaders(device, &mut engine, &options)?; |
| #[cfg(not(target_arch = "wasm32"))] |
| engine.build_shaders_if_needed(device, options.num_init_threads); |
| let blit = options |
| .surface_format |
| .map(|surface_format| BlitPipeline::new(device, surface_format)); |
| |
| Ok(Self { |
| options, |
| engine, |
| shaders, |
| blit, |
| target: None, |
| // Use 3 pending frames |
| #[cfg(feature = "wgpu-profiler")] |
| profiler: GpuProfiler::new(GpuProfilerSettings { |
| ..Default::default() |
| })?, |
| #[cfg(feature = "wgpu-profiler")] |
| profile_result: None, |
| }) |
| } |
| |
| /// Renders a scene to the target texture. |
| /// |
| /// The texture is assumed to be of the specified dimensions and have been created with |
| /// the [`wgpu::TextureFormat::Rgba8Unorm`] format and the [`wgpu::TextureUsages::STORAGE_BINDING`] |
| /// flag set. |
| pub fn render_to_texture( |
| &mut self, |
| device: &Device, |
| queue: &Queue, |
| scene: &Scene, |
| texture: &TextureView, |
| params: &RenderParams, |
| ) -> Result<()> { |
| let (recording, target) = render::render_full(scene, &self.shaders, params); |
| let external_resources = [ExternalResource::Image( |
| *target.as_image().unwrap(), |
| texture, |
| )]; |
| self.engine.run_recording( |
| device, |
| queue, |
| &recording, |
| &external_resources, |
| "render_to_texture", |
| #[cfg(feature = "wgpu-profiler")] |
| &mut self.profiler, |
| )?; |
| #[cfg(feature = "wgpu-profiler")] |
| { |
| let mut encoder = |
| device.create_command_encoder(&wgpu::CommandEncoderDescriptor { label: None }); |
| self.profiler.resolve_queries(&mut encoder); |
| queue.submit(Some(encoder.finish())); |
| self.profiler.end_frame().unwrap(); |
| } |
| Ok(()) |
| } |
| |
| /// Renders a scene to the target surface. |
| /// |
| /// This renders to an intermediate texture and then runs a render pass to blit to the |
| /// specified surface texture. |
| /// |
| /// The surface is assumed to be of the specified dimensions and have been configured with |
| /// the same format passed in the constructing [`RendererOptions`]' `surface_format`. |
| /// Panics if `surface_format` was `None` |
| pub fn render_to_surface( |
| &mut self, |
| device: &Device, |
| queue: &Queue, |
| scene: &Scene, |
| surface: &SurfaceTexture, |
| params: &RenderParams, |
| ) -> Result<()> { |
| let width = params.width; |
| let height = params.height; |
| let mut target = self |
| .target |
| .take() |
| .unwrap_or_else(|| TargetTexture::new(device, width, height)); |
| // TODO: implement clever resizing semantics here to avoid thrashing the memory allocator |
| // during resize, specifically on metal. |
| if target.width != width || target.height != height { |
| target = TargetTexture::new(device, width, height); |
| } |
| self.render_to_texture(device, queue, scene, &target.view, params)?; |
| let blit = self |
| .blit |
| .as_ref() |
| .expect("renderer should have configured surface_format to use on a surface"); |
| let mut encoder = |
| device.create_command_encoder(&wgpu::CommandEncoderDescriptor { label: None }); |
| { |
| let surface_view = surface |
| .texture |
| .create_view(&wgpu::TextureViewDescriptor::default()); |
| let bind_group = device.create_bind_group(&wgpu::BindGroupDescriptor { |
| label: None, |
| layout: &blit.bind_layout, |
| entries: &[wgpu::BindGroupEntry { |
| binding: 0, |
| resource: wgpu::BindingResource::TextureView(&target.view), |
| }], |
| }); |
| let mut render_pass = encoder.begin_render_pass(&wgpu::RenderPassDescriptor { |
| label: None, |
| color_attachments: &[Some(wgpu::RenderPassColorAttachment { |
| view: &surface_view, |
| resolve_target: None, |
| ops: wgpu::Operations { |
| load: wgpu::LoadOp::Clear(wgpu::Color::default()), |
| store: wgpu::StoreOp::Store, |
| }, |
| })], |
| depth_stencil_attachment: None, |
| occlusion_query_set: None, |
| timestamp_writes: None, |
| }); |
| #[cfg(feature = "wgpu-profiler")] |
| let mut render_pass = self |
| .profiler |
| .scope("blit to surface", &mut render_pass, device); |
| render_pass.set_pipeline(&blit.pipeline); |
| render_pass.set_bind_group(0, &bind_group, &[]); |
| render_pass.draw(0..6, 0..1); |
| } |
| #[cfg(feature = "wgpu-profiler")] |
| self.profiler.resolve_queries(&mut encoder); |
| queue.submit(Some(encoder.finish())); |
| self.target = Some(target); |
| #[cfg(feature = "wgpu-profiler")] |
| { |
| self.profiler.end_frame().unwrap(); |
| if let Some(result) = self |
| .profiler |
| .process_finished_frame(queue.get_timestamp_period()) |
| { |
| self.profile_result = Some(result); |
| } |
| } |
| Ok(()) |
| } |
| |
| /// Reload the shaders. This should only be used during `vello` development |
| #[cfg(feature = "hot_reload")] |
| pub async fn reload_shaders(&mut self, device: &Device) -> Result<()> { |
| device.push_error_scope(wgpu::ErrorFilter::Validation); |
| let mut engine = WgpuEngine::new(self.options.use_cpu); |
| // We choose not to initialise these shaders in parallel, to ensure the error scope works correctly |
| let shaders = shaders::full_shaders(device, &mut engine, &self.options)?; |
| let error = device.pop_error_scope().await; |
| if let Some(error) = error { |
| return Err(error.into()); |
| } |
| self.engine = engine; |
| self.shaders = shaders; |
| Ok(()) |
| } |
| |
| /// Renders a scene to the target texture. |
| /// |
| /// The texture is assumed to be of the specified dimensions and have been created with |
| /// the [`wgpu::TextureFormat::Rgba8Unorm`] format and the [`wgpu::TextureUsages::STORAGE_BINDING`] |
| /// flag set. |
| /// |
| /// The return value is the value of the `BumpAllocators` in this rendering, which is currently used |
| /// for debug output. |
| /// |
| /// This return type is not stable, and will likely be changed when a more principled way to access |
| /// relevant statistics is implemented |
| pub async fn render_to_texture_async( |
| &mut self, |
| device: &Device, |
| queue: &Queue, |
| scene: &Scene, |
| texture: &TextureView, |
| params: &RenderParams, |
| ) -> Result<Option<BumpAllocators>> { |
| let mut render = Render::new(); |
| let encoding = scene.encoding(); |
| // TODO: turn this on; the download feature interacts with CPU dispatch |
| let robust = true; |
| let recording = render.render_encoding_coarse(encoding, &self.shaders, params, robust); |
| let target = render.out_image(); |
| let bump_buf = render.bump_buf(); |
| self.engine.run_recording( |
| device, |
| queue, |
| &recording, |
| &[], |
| "t_async_coarse", |
| #[cfg(feature = "wgpu-profiler")] |
| &mut self.profiler, |
| )?; |
| |
| let mut bump: Option<BumpAllocators> = None; |
| if let Some(bump_buf) = self.engine.get_download(bump_buf) { |
| let buf_slice = bump_buf.slice(..); |
| let (sender, receiver) = futures_intrusive::channel::shared::oneshot_channel(); |
| buf_slice.map_async(wgpu::MapMode::Read, move |v| sender.send(v).unwrap()); |
| if let Some(recv_result) = receiver.receive().await { |
| recv_result?; |
| } else { |
| return Err("channel was closed".into()); |
| } |
| let mapped = buf_slice.get_mapped_range(); |
| bump = Some(bytemuck::pod_read_unaligned(&mapped)); |
| } |
| // TODO: apply logic to determine whether we need to rerun coarse, and also |
| // allocate the blend stack as needed. |
| self.engine.free_download(bump_buf); |
| // Maybe clear to reuse allocation? |
| let mut recording = Recording::default(); |
| render.record_fine(&self.shaders, &mut recording); |
| let external_resources = [ExternalResource::Image(target, texture)]; |
| self.engine.run_recording( |
| device, |
| queue, |
| &recording, |
| &external_resources, |
| "t_async_fine", |
| #[cfg(feature = "wgpu-profiler")] |
| &mut self.profiler, |
| )?; |
| Ok(bump) |
| } |
| |
| /// See [`Self::render_to_surface`] |
| pub async fn render_to_surface_async( |
| &mut self, |
| device: &Device, |
| queue: &Queue, |
| scene: &Scene, |
| surface: &SurfaceTexture, |
| params: &RenderParams, |
| ) -> Result<Option<BumpAllocators>> { |
| let width = params.width; |
| let height = params.height; |
| let mut target = self |
| .target |
| .take() |
| .unwrap_or_else(|| TargetTexture::new(device, width, height)); |
| // TODO: implement clever resizing semantics here to avoid thrashing the memory allocator |
| // during resize, specifically on metal. |
| if target.width != width || target.height != height { |
| target = TargetTexture::new(device, width, height); |
| } |
| let bump = self |
| .render_to_texture_async(device, queue, scene, &target.view, params) |
| .await?; |
| let blit = self |
| .blit |
| .as_ref() |
| .expect("renderer should have configured surface_format to use on a surface"); |
| let mut encoder = |
| device.create_command_encoder(&wgpu::CommandEncoderDescriptor { label: None }); |
| { |
| let surface_view = surface |
| .texture |
| .create_view(&wgpu::TextureViewDescriptor::default()); |
| let bind_group = device.create_bind_group(&wgpu::BindGroupDescriptor { |
| label: None, |
| layout: &blit.bind_layout, |
| entries: &[wgpu::BindGroupEntry { |
| binding: 0, |
| resource: wgpu::BindingResource::TextureView(&target.view), |
| }], |
| }); |
| let mut render_pass = encoder.begin_render_pass(&wgpu::RenderPassDescriptor { |
| label: None, |
| color_attachments: &[Some(wgpu::RenderPassColorAttachment { |
| view: &surface_view, |
| resolve_target: None, |
| ops: wgpu::Operations { |
| load: wgpu::LoadOp::Clear(wgpu::Color::default()), |
| store: wgpu::StoreOp::Store, |
| }, |
| })], |
| depth_stencil_attachment: None, |
| timestamp_writes: None, |
| occlusion_query_set: None, |
| }); |
| #[cfg(feature = "wgpu-profiler")] |
| let mut render_pass = self |
| .profiler |
| .scope("blit to surface", &mut render_pass, device); |
| render_pass.set_pipeline(&blit.pipeline); |
| render_pass.set_bind_group(0, &bind_group, &[]); |
| render_pass.draw(0..6, 0..1); |
| } |
| #[cfg(feature = "wgpu-profiler")] |
| self.profiler.resolve_queries(&mut encoder); |
| queue.submit(Some(encoder.finish())); |
| self.target = Some(target); |
| #[cfg(feature = "wgpu-profiler")] |
| { |
| self.profiler.end_frame().unwrap(); |
| if let Some(result) = self |
| .profiler |
| .process_finished_frame(queue.get_timestamp_period()) |
| { |
| self.profile_result = Some(result); |
| } |
| } |
| Ok(bump) |
| } |
| } |
| |
| #[cfg(feature = "wgpu")] |
| struct TargetTexture { |
| view: TextureView, |
| width: u32, |
| height: u32, |
| } |
| |
| #[cfg(feature = "wgpu")] |
| impl TargetTexture { |
| pub fn new(device: &Device, width: u32, height: u32) -> Self { |
| let texture = device.create_texture(&wgpu::TextureDescriptor { |
| label: None, |
| size: wgpu::Extent3d { |
| width, |
| height, |
| depth_or_array_layers: 1, |
| }, |
| mip_level_count: 1, |
| sample_count: 1, |
| dimension: wgpu::TextureDimension::D2, |
| usage: wgpu::TextureUsages::STORAGE_BINDING | wgpu::TextureUsages::TEXTURE_BINDING, |
| format: wgpu::TextureFormat::Rgba8Unorm, |
| view_formats: &[], |
| }); |
| let view = texture.create_view(&wgpu::TextureViewDescriptor::default()); |
| Self { |
| view, |
| width, |
| height, |
| } |
| } |
| } |
| |
| #[cfg(feature = "wgpu")] |
| struct BlitPipeline { |
| bind_layout: wgpu::BindGroupLayout, |
| pipeline: wgpu::RenderPipeline, |
| } |
| |
| #[cfg(feature = "wgpu")] |
| impl BlitPipeline { |
| fn new(device: &Device, format: TextureFormat) -> Self { |
| const SHADERS: &str = r#" |
| @vertex |
| fn vs_main(@builtin(vertex_index) ix: u32) -> @builtin(position) vec4<f32> { |
| // Generate a full screen quad in normalized device coordinates |
| var vertex = vec2(-1.0, 1.0); |
| switch ix { |
| case 1u: { |
| vertex = vec2(-1.0, -1.0); |
| } |
| case 2u, 4u: { |
| vertex = vec2(1.0, -1.0); |
| } |
| case 5u: { |
| vertex = vec2(1.0, 1.0); |
| } |
| default: {} |
| } |
| return vec4(vertex, 0.0, 1.0); |
| } |
| |
| @group(0) @binding(0) |
| var fine_output: texture_2d<f32>; |
| |
| @fragment |
| fn fs_main(@builtin(position) pos: vec4<f32>) -> @location(0) vec4<f32> { |
| let rgba_sep = textureLoad(fine_output, vec2<i32>(pos.xy), 0); |
| return vec4(rgba_sep.rgb * rgba_sep.a, rgba_sep.a); |
| } |
| "#; |
| |
| let shader = device.create_shader_module(wgpu::ShaderModuleDescriptor { |
| label: Some("blit shaders"), |
| source: wgpu::ShaderSource::Wgsl(SHADERS.into()), |
| }); |
| let bind_layout = device.create_bind_group_layout(&wgpu::BindGroupLayoutDescriptor { |
| label: None, |
| entries: &[wgpu::BindGroupLayoutEntry { |
| visibility: wgpu::ShaderStages::FRAGMENT, |
| binding: 0, |
| ty: wgpu::BindingType::Texture { |
| sample_type: wgpu::TextureSampleType::Float { filterable: true }, |
| view_dimension: wgpu::TextureViewDimension::D2, |
| multisampled: false, |
| }, |
| count: None, |
| }], |
| }); |
| let pipeline_layout = device.create_pipeline_layout(&wgpu::PipelineLayoutDescriptor { |
| label: None, |
| bind_group_layouts: &[&bind_layout], |
| push_constant_ranges: &[], |
| }); |
| let pipeline = device.create_render_pipeline(&wgpu::RenderPipelineDescriptor { |
| label: None, |
| layout: Some(&pipeline_layout), |
| vertex: wgpu::VertexState { |
| module: &shader, |
| entry_point: "vs_main", |
| buffers: &[], |
| }, |
| fragment: Some(wgpu::FragmentState { |
| module: &shader, |
| entry_point: "fs_main", |
| targets: &[Some(wgpu::ColorTargetState { |
| format, |
| blend: None, |
| write_mask: wgpu::ColorWrites::ALL, |
| })], |
| }), |
| primitive: wgpu::PrimitiveState { |
| topology: wgpu::PrimitiveTopology::TriangleList, |
| strip_index_format: None, |
| front_face: wgpu::FrontFace::Ccw, |
| cull_mode: Some(wgpu::Face::Back), |
| polygon_mode: wgpu::PolygonMode::Fill, |
| unclipped_depth: false, |
| conservative: false, |
| }, |
| depth_stencil: None, |
| multisample: wgpu::MultisampleState { |
| count: 1, |
| mask: !0, |
| alpha_to_coverage_enabled: false, |
| }, |
| multiview: None, |
| }); |
| Self { |
| bind_layout, |
| pipeline, |
| } |
| } |
| } |